TECHNICAL REPORT
| Grantee |
Louise Dolphin
|
| Project Title | Network coding over satellite links: scheduling redundancy for better goodput |
| Amount Awarded | US$20,000 |
| Dates covered by this report: | 2020-09-04 to 2020-09-04 |
| Report submission date | 2020-08-14 |
| Economies where project was implemented | New Zealand |
| Project leader name |
Ulrich Speidel
|
| Project Team |
Fuli Junior Elvis Fuli
[email protected]
Wanqing Tu
[email protected]
|
| Partner organization | Steinwurf ApS, Aalborg, Denmark |
Project Summary
Many Pacific islands still rely on satellite for Internet access, using narrowband links with capacities far below those of the networks at either end, carrying mostly TCP (Transmission Control Protocol) traffic. On these links, a large number of TCP senders simultaneously try to adjust their congestion windows to the perceived link capacity: Acknowledgment (ACK) packets prompt congestion window increases; overdue ACKs shrink window sizes exponentially. The long link latency means that senders thus get an extremely outdated picture of the available capacity, often leading to excessive queue oscillation, where the link input buffer overflows and drains entirely within seconds. Complete drainage means idle link capacity, while overflows impede large TCP transfers. Our experiments in the islands have shown that sending coded packets with redundancy for a small numbers of such transfers can increase goodput by concealing some overflow tail drops. Under our last two ISIF grants, we built a simulator to investigate coding of all flows for such island links. This showed that coding is extremely time-sensitive: Coded packets must result in ACKs before TCP retransmits, but must also not hit the input buffer during overflows, a common occurrence in our first generation encoder. Our previous ISIF-funded project added a delay to the coded packets, resulting in more arrivals and increased goodput when the delay happened to coincide with link capacity. This is a hit-and-miss game, however: coded packets may be sent too late and often still hit queue overflows. Moreover, when surplus coded packets make it into the buffer, they add to the round-trip-time for all other TCP senders with subsequent packets in the queue. The current project leverages a new feature in our coding software, which lets us distinguish coded packets from "original" packets on the wire. We have implemented a queueing system that only feeds coded packets into the "original" buffer once this queue drains below a configured size, and can now also drop surplus coded packets. Simulations to date show that this leads to a significant increase in goodput on large monopoly flows over the conventional coding, and we are currently investigating how the queueing system parameters must be best chosen to allow this gain to extend to cumulative goodput of a large mix of flows of different sizes, as encountered on such links.
Table of contents
- Project factsheet information
- Background and justification
- Project Implementation
- Project Evaluation
- Gender Equality and Inclusion
- Project Communication Strategy
- Recommendations and Use of Findings
- Bibliography
Background and Justification
Context: The University of Auckland in New Zealand's top-ranking research university, and its School of Computer Science ranks in the top 100 globally. Auckland is also the world's largest Polynesian city, with a large diaspora of Pacific Islanders. In some cases (e.g., Cook Islands, Niue, Tokelau), this diaspora is several times larger than the current population in the respective islands, which often depend on remittances from that diaspora and trade very closely with it. The lead researcher wears another hat as support liaison officer for Pacific students in his School, which attracts several hundred course enrolments from Pacific Island students each year. In this role, he has seen this close relationship between diaspora and the islands many times. For example, a few years ago we tried to support a desperate female student stuck in Tonga after having been ordered there to look after an elderly relative who could not travel to NZ as orginally planned. The student was unable to access course materials due to slow Internet access. Another common example are student groups trying to support their communities after a cyclone or a tsunami, with some having to support family members in the islands who have lost their home to the elements. Covid-19 has since further highlighted this relationship, with New Zealand acting as a gateway and - of late - as a protective gatekeeper to Covid-19-free Pacific islands.
This creates a huge need for communication between the islands and New Zealand, as well as other places where islanders live: Australia, the US, Hawaii, and Japan. Internet connectivity is key in all cases.
Main challenges: Distance is a real curse in this context, both in terms of travel but also in terms of bringing Internet access to the islands, many of have a low per capita GDP. With Covid-19, the fact that the sea is also an international border to and between Pacific Island states has further complicated this. In terms of connectivity provisioning, satellites have a comparatively low entry cost, but the cost of bandwidth is very high and the long signal round-trip times of satellite links impact significantly on the performance. Breakdowns and outages of cables and satellite links, e.g., due to technical failure or natural disaster, are strongly felt in Auckland as well, as seen during Tonga's cable outage in early 2019.
In recent years, many of the more highly populated islands have been able to secure connections to the international submarine fibre networks. This is a double-edged sword, however: On the one hand, it moves potential connection points closer to some of the smaller islands, on the other hand, it shrinks the customer pool for satellite providers, keeping the cost high. Moreover, it is currently very much unclear quite how much relief, if any, the much awaited global LEO (low earth orbit) satellite constellations will bring, such as StarLink, Amazon's Project Kuiper, or OneWeb.
To add insult to injury, satellite links present high latency bottlenecks on the Internet, which causes problems if they are being used to provision a larger number of end users on the island. The Internet's main transport protocol, TCP, relies on end-to-end feedback when determining the amount of data to entrust to a bottleneck. It is designed to increase this amount relatively slowly while feedback indicates that bottleneck capacity is available, while backing off exponentially once the feedback stops. The long latency of satellite links unfortunately means that the feedback paints a very outdated picture of the available capacity, which can trick senders into an inappropriate response: backing off when capacity is available, and sending more data when there is no capacity. Moreover, the "bottleneck experience" is the same for all TCP connections across a satellite link: Either there is capacity, or there is not. This synchronises the senders into an oscillation pattern which can leave the link idle for short periods of time, while simultaneously decreasing the data rates of senders that have a lot of data to transfer up to the point of suppression. The net result: Island ISPs don't really see their traffic reach the capacity they are paying for, while their customers complain.
Existing approaches: The oldest "solution" to this problem is to deploy more buffer memory at the input buffers to the satellite links, a practice adopted from router configuration that has long since been abandoned in that domain because it causes bufferbloat, a condition where the buffers simply always contain a significant amount of data and do not act as the shock absorbers they are meant to be. Another technique in common use are performance-enhancing proxies (PEPs), which exist in various flavours. For all we are able to tell (many PEPs are closed source black boxes), all PEPs interfere with the Internet's end-to-end principle to some extent, however, so can in some circumstances result in bogus feedback to the sender (data being counted as delivered when in fact it has not been). Our own investigations confirm that they do offer some goodput benefit over baseline, however.
Coding: Around seven years ago, the idea emerged to use error-correcting network codes [1] across the input buffer to compensate for some of the packets losses caused by buffer overflows. This allows us to use spare capacity on the link at a later point in time to send redundancy data which lets us reconstruct lost packets from that data and packets that have already crossed the link successfully. This allows us to dampen TCP's oscillations somewhat. Our experiments in the Cook Islands and Tuvalu using random linear network codes (RLNC) have shown that this can claw back significant amounts of lost goodput during busy hours of the day. These experiments investigated individual large transfers only, though. To be able to investigate what would happen if we coded all TCP traffic to an island, we had to head back to the lab and build a simulator.
The Auckland Satellite Internet Simulator: Subsequently, we spent a few years building and expanding the Auckland Satellite Internet Simulator [2], a hardware based simulator capable of real-time simulation of up to several thousand simultaneous connections across a simulated satellite link. With over 140 computers, it is now a significant resource in our School. It can at present simulate both geostationary (GEO) and medium-earth orbit (MEO) with coding and/or PEPs applied as required.
What we learned from the simulator: Initially, we used the simulator to establish whether current practice in terms of input buffer dimensioning was in fact best practice, given that most providers currently still configure buffer capacities in the order of 1 to 4 times the link's bandwidth-delay product, a practice that has long been called into question on routers as it contributes to bufferbloat [3, 4]. Experimenting with a large number of different buffer sizes, we found the current practice to be inadequate indeed [5]. We were also able to reliably reproduce the excessive TCP queue oscillation patterns seen in the wild. We also learned that when one simulates the Internet traffic to an island, it is important to consider that most TCP connections on the "real" Internet are very short and consist of a few packets only. These do not benefit as much from coding as many transfers are complete by the time the feedback arrives at the sender, but they contribute to the queues nevertheless, and we are able to show that genuinely overloaded links with close to 100% utilisation carry predominantly this type of traffic. We also learned that redundancy data sent too early risks getting lost to exactly the same buffer overflows that dropped the original packets, while sending it with significant delay meant that the redundancy data was itself made redundant by the retransmissions from the TCP senders. Trying to find a delay that would work proved to be a hit-and-miss approach, while much of the redundancy data that made it into the input buffer was actually not needed because the original packets had already gone successfully past that point. To make matters worse: The surplus redundancy was now contributing to the round-trip-time of earlier packets. So we were looking for a better way.
A better way? It became clear that what we needed was a way of injecting redundancy only at times when there was capacity in the input buffer, and to keep surplus redundancy out. If successful, then hopefully this will let us use the spare capacity on the links to carry just as much redundancy as is needed, and therefore let TCP expand into a significant part of the remaining spare capacity. This should then hopefully lead to better link utilisation, making satellite links a little more economical and useful for their end users.
Project Implementation
Coded satellite links
The challenge before us was to find a way in which we could inject redundancy into the input buffer on a capacity-available basis while keeping surplus redundancy out. To understand what we are doing here, it pays to consider the components of a a coded satellite link shown below:
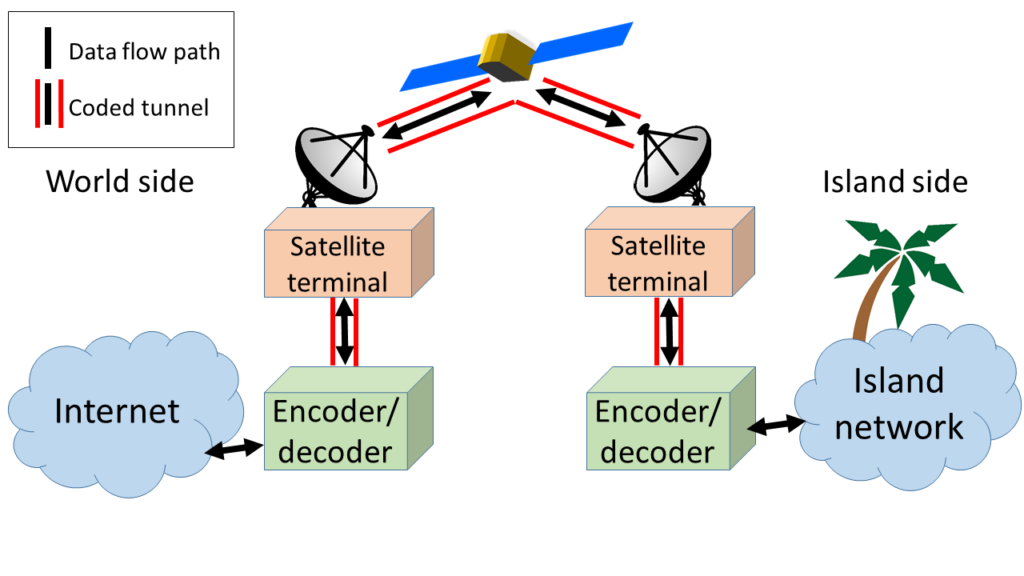
In this link, TCP/IP packets travelling from, say, the Internet to the island side, first encounter the world-side encoder. This encoder stops the incoming packets, and for each set of N incoming packets generates two types of packets which it then forwards towards the satellite link itself:
- A set of N packets that are systematically coded. Each of these encapsulates a single one of the original packets with a coding header that identifies which set (also called a generation) the packet belongs to. The encoder generates and forwards these packets the moment the corresponding original packet arrives at the encoder. When these packets arrive at the decoder, the decoder can decode them immediately by stripping the coding header and releasing the original packet into the island network.
- A set of M randomly coded packets that carry the redundancy. Each of these is a random linear combination of all N original packets: For the i-th randomly coded packet, the encoder generates a pseudorandom number for each of the original N packets to multiply each byte in that original packet with. It then adds the results for each byte in the same position in each of the N original packets. These results, together with a coding header that contains the generation number and the seed for the random generator, form the i-th randomly coded packet that the encoder then sends to the link.
Both types of packets are encapsulated as UDP and are addressed to the decoder at the far end of the link. The link may now drop one or more of these packets when the input queue overflows. The randomly coded packets still arrive at the decoder after the systematically coded ones, however. When the decoder notices that one or more of the systematically coded packets are missing (because they have been dropped or damaged in transit), the decoder can attempt to recover them with the help of the randomly coded packets by forming and solving a system of linear equations. For this purpose, the decoder needs to have a total of N systematically and randomly coded packets available, but no more than that. That is, the link may drop up to M of the packets in the generation.
Titration
The question was now how to ensure that randomly coded packets didn't reach the link if the link buffer had already accepted N systematically and/or randomly coded packets for delivery, and there was hence no longer a risk of queue overflow for the generation concerned. For this purpose, we inserted an additional device into the flow path to the link on either side:
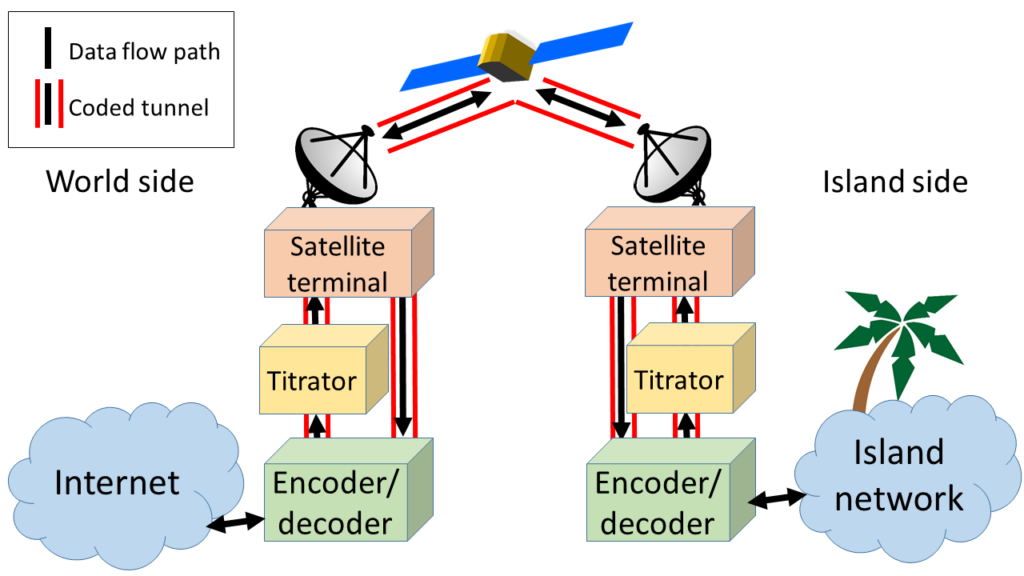
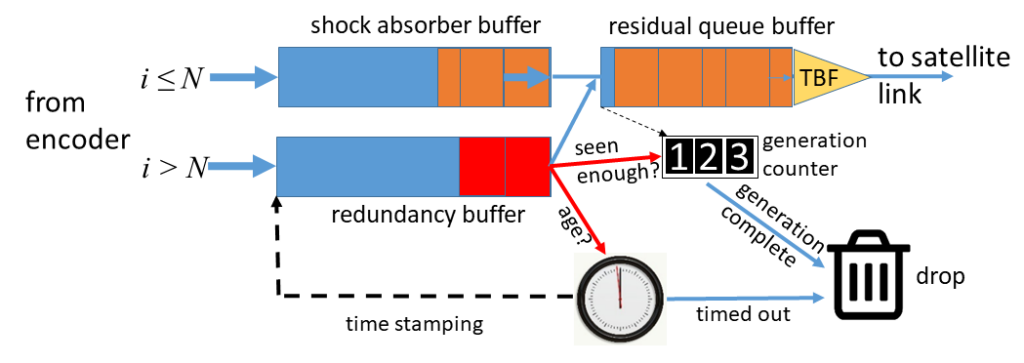
We call this device a titrator, as it brings the bottleneck forward and feeds the traffic into the satellite link at pretty much exactly the link rate. The titrator therefore also takes over the buffering role, but instead of providing just a single first-in-first-out buffer, it provides three. The following figure shows these:
The titrator inspects the incoming coded packets to determine whether they are systematically or randomly coded. In practice, we do this by sending the two types to different UDP ports at the decoder, a small change to the coding software that the software maintainers, Steinwurf ApS of Aalborg, Denmark, kindly implemented for us.
Any packet that is a UDP packet for the redundancy port of the decoder is enqueued in the redundancy buffer, a byte FIFO. All other packets destined for the link are put into the shock absorber buffer, another byte FIFO which effectively takes over the lion's share of the capacity previously provisioned at the link input buffer. Its capacity does not have to be the same as the shock absorber buffer.
The residual queue buffer is also a byte FIFO and sits in front of a plain token bucket filter, which limits the peak rate at which packets can progress to the satellite link. Its capacity makes up the remainder of the capacity previously provisioned at the link input buffer. When the residual queue buffer has capacity, it refills by dequeueing from the shock absorber queue with priority. In doing so, it keeps count of the number of packets it has seen for each generation. When the shock absorber queue is empty, the residual queue buffer attempts to refill from the redundancy buffer instead. In doing so, it inspects every packet in the redundancy buffer according to two criteria:
- Is the packet still required? If the residential queue buffer has already seen N packets for the generation that the packet at the head of the redundancy buffer is part of, the packet is surplus to requirements and gets discarded.
- Is the packet still current? If the residential queue buffer has not yet seen N packets for the generation in question, but the packet has been waiting in the redundancy buffer for an amount of time larger than the likely TCP timeout for the connection in question, retransmissions for the missing packets will already be on their way, rendering the packet in the redundancy queue surplus to requirements (strictly speaking, releasing this packet could make the retransmission redundant, but since we have no easy means of intercepting the latter, it is best to drop the randomly coded packet here). For this purpose, each packet enqueued in the redundancy queue is accompanied by a time stamp that records the time it was enqueued.
This ensures that in general only relevant randomly coded packets make it into the residential queue buffer and therefore onto the link. The priority dequeueing from the shock absorber queue also ensures that the randomly coded packets do not contribute significantly to queue overflows. The actual input buffer at the satellite link can now be very small - all it needs to buffer is the jitter introduced between the titrator and the link itself, which is now at most a couple of packets.
Implementation and testing
The titrator software was written over the summer 2019/2020. Its integration into the simulator required two titrator machines to be added to the simulator's satellite link chain of machines, which in turn required adaptation of the simulator's network topology to account for the introduction of two new subnets in the chain. While the titrator could in principle run on the encoder machine as well, we considered it advisable to run it on its own box, which allows us to inspect the incoming coded traffic separately with a copper tap. We also had to upgrade the simulator's software harness that orchestrates the startup and shutdown of all simulator functional components during an experiment in order to start the titrator functionality at an appropriate time.
This work was essentially complete by early March 2020, ready to start testing and debugging. The primary investigator then left for a two week conference / academic visit trip to North America, which put a temporary stop to the work. The trip was abridged when Covid-19 hit, but necessitated self-isolation on return, which limited the kind of work that could be undertaken to remote tasks. Fortunately, this was largely all that was required at that point in time, and we were able to test and debug the program and fix any remaining memory leaks.
The simulator
Tests of the titrator were conducted on the Auckland Satellite Simulator Facility, which consists of multiple networks:
- A "satellite link chain" of seven SuperMicro servers connected in series on a line topology. The centre (4th) server emulates the satellite link itself, i.e., implements the latency, bandwidth and buffer constraints that satellite link would impose. The remaining three servers on either side act as plain routers in baseline experiments. In experiments with PEPs, the outermost servers (1st and 7th) on the network act as PEPs. Approaching the satellite emulator from either side, the 2nd and 6th server act as network coders and decoders, and the 3rd and 5th run the titrator software. Each server is connected to its neighbour via a dedicated IP subnet. Within all but two of these subnets, network test access points (NTAPs) provide a copy of the island-bound traffic to one of two capture servers.
- A "world" network of 24 SuperMicro servers connected to one end of the satellite link chain via switches. The 22 machines ("world servers") provide the payload data for the background traffic to the "island" side of the simulator. Each of the servers has an ingress and egress delay configured to mimic the terrestrial delay between a server on the Internet and a satellite ground station. The remaining two servers provide a fixed-time TCP transfer and a rapid-fire ping measurement during each experiment. A lone Raspberry Pi on the world network acts as a signalling "referee" that injects a unique signal packet into each experiment at the start and end of the experiment time.
- An "island" network of 96 Raspberry Pis running Raspbian and 10 Intel NUCs running Ubuntu acting as "island-based" client machines, connected to the other end of the satellite link chain. Their job is to request the background traffic from the world servers. A 97th Raspberry Pi acts as an interface to the campus network.
- A command and control network in the form of the university's campus network, linking a central command and control server to the machines on the "world" network, on the satellite link chain, and the capture servers. The command and control server also has an interface on one of the island-side and world-side switches, respectively.
- A storage network linking the command and control server to two large storage servers with 96 TB of raided storage each.
Experiment procedure
Each experiment starts with the setting up of the satellite link chain, which initially begins with the setup of the satellite emulator itself, with all other machines on the satellite link chain in router configuration only. This is then followed by a link test and setup of any coding, titrating, or PEP functionality required on the respective servers. Next comes a test of all interfaces that should be reachable from the command and control machine.
We then start an iperf3 server on one of the NUCs to act as the fixed-time TCP transfer receipient later during the experiment. This is followed by the activation of the packet captures on the capture servers. When doing so, we activate captures from the NTAPs progressively from the island end towards the world end. This is to ensure that any packet seen in a capture closer to the world side will also appear in the downstream captures unless it is genuinely lost.
Before starting the world servers, we reset the path MTU (PMTU) cache on all world servers to ensure that none can benefit from path MTU information gleaned from a previous experiment. We then start the world servers, which are now ready to accept incoming connections from the island side. When receiving such connections, the servers randomly select a flow size from a distribution and return a corresponding amount of data to the client before disconnecting the client.
The next step is to start the clients. To be able to simulate a controlled demand, we compute how many of the island client machines will be involved, and how many parallel connections (channels) each of these machines should manage for a given demand level. This information is then used to start the clients in the correct configuration.
We then allow ten seconds for ramp-up of the background traffic. After this time, we instruct the lone Raspberry Pi on the world side to send a special "start" UDP packet to a specific port on the server on the satellite link chain that connects to the island network. This server runs a relay program that rebroadcasts this packet to all island clients. The packet acts as a kind of "referee whistle" that starts the main experiment period. It is visible in all captures, thereby establishing a common reference point in time, and also commands all clients to start counting the goodput they receive from their transport layer.
The main experiment period runs for 600 seconds in the case low bitrate of GEO links. With higher bit rates, data accrues more quickly, meaning that we can reduce this to about 90 seconds on 320 Mb/s MEO links. Immediately after the start, we also start a rapid-fire ping series from the world side to the island side, which allows us to coarsely monitor the fill level of the satellite link input queue (the only queue with significant sojourn time). We then also start an iperf3 transfer for half of the experiment period (300 seconds for low bitrate GEO).
At the end of the 600 seconds, we let the lone Raspberry Pi "whistle" again. This causes the clients to stop counting goodput and shut down. We then shut down the world servers and captures explicity, in the latter case, we terminate starting from the world end.
The capture servers then transfer the captures to the command an control machine, which meanwhile retrieves the goodput information from the island clients and the iperf3 and ping information from the servers on the world side.
This is then automatically analysed for, among others, total goodput and iperf3 goodput seen on the island side. The aim of our research is of course to improve on both, rather than on one at the expense of the other.
A complete experiment takes around 20 minutes mostly depending on the demand level. The main experiment period is only one component of this as experiments with shorter main experiment periods also run at larger demand levels and result in larger trace files, which take longer to transfer and analyse.
Single-flow experiments
To test the theory of its working, we moved on to single-flow experiments, where we ran two-minute tests using iperf3 across a simulated 16 Mbps geostationary satellite link without background traffic and 80 millisecond terrestrial one-way latency at the world end. The untitrated base cases were and uncoded and coded link. The latter used up to M=6 redundancy packets on an N=60 generation code. The titrated experiments used the same code but shifted all but 10 kB of the satellite link input buffer capacity to the titrator, where 10 kB were assigned to the residual queue buffer and the rest to the shock absorber buffer. The redundancy buffer was configured with a generous 2000 kB capacity and timeouts in the range of the expected bare-bones round-trip time plus queue sojourn time.
From our island experiments, we already knew that coding on its own (without titration) would work well here. Uncoded goodput after 2 minutes clocked it at around 8.7 Mbps in a series of 10 experiments with a 120 kB input buffer. With coding added, this rose to 12 Mbps, and with titration to 12.8 Mbps. Gains of this nature and magnitude were observed for other input buffer sizes as well. Comparing against bufferbloat-inducing large input buffers, we found that a 500 kB input queue, when coded and titrated, gave around 0.8 Mbps higher goodput than an uncoded but more conventionally-sized input 2000 kB input buffer. This result shows that coded and titrated links have a benefit even in such uncritical scenarios. A paper with these results was submitted to IEEE Globecom, but ended up with referees that were less familiar with the topic area than those for our two previous publications in this venue.
First experiments with background traffic - and a late insight that changed everything
These experiments have started but are still ongoing. During the full Covid-19 lockdown in New Zealand, we did not have physical access to the simulator laboratory and sadly, the "health" of the simulator deteriorated during this period. This was mostly due to our large fleet of 96 Raspberry Pis on the "island" side of the simulator developing problems with SD card memory or power supply. What would normally have been a quick 30 minute repair job now became a nigh impossible mission. This didn't affect our single-flow experiments since these can use any machine on the island side as an endpoint, provided that the remaining simulator network core and satellite chain systems are up. Eventually, one of the satellite chain machines crashed as well, and we had to await physical access to be able to reboot. Meanwhile, we upgraded our experiment harness further so we could tag individual Raspberry Pi machines as "unavailable", allowing the experiment software to work around them. This proved helpful later on during subsequent lockdowns.
First results from the experiments showed a small gain from the use of the titrator, however not as much as we had hoped for. Varying parameters did not seem to make much difference.
The breakthrough eventually came from an unexpected corner. We performed an operating system upgrade on the satellite emulator machine, the heart of the simulator. This machine acts like a router between the "island" and "world" sides and imposes both the bandwidth constraint and the delay associated with a satellite link. To this end, the machine used a combination of token bucket filters and intermediate function block devices to constrain the bandwidth on ingress, and a netem delay queue on egress. Both the token bucket filter and the netem delay queue are part of the tc "traffic control" tool that comes with Ubuntu. We had hitherto tested link emulations with this arrangement using a combination of an iperf3 bandwidth test and a simultaneous ping test to verify the delay. After the upgrade to Ubuntu 20.04, our tc setup suddenly failed this test in most cases, with swathes of packets lost early on in its operation, a condition that either then disappeared or persisted until the tc elements were removed and reintroduced.
Trying to figure out whether it was the test tools that had failed or the tc arrangement, we wrote a dedicated link testing software.
The dedicated testing software
The new software runs a four-stage process to test the link that uses sequence numbered and padded UDP packets with timestamps that the test client sends to a server at the far end of the link. The server returns the packets to the client, without padding so as not to load the return link more than absolutely need be.
In the first of the four stages, the software feeds the emulated link at (just below) its nominal rate. In reality, we would expect this to result in a bare-bones round-trip-time (RTT) and at best sporadic packet loss (in the absence of background traffic). The client tests for that by checking whether any sequence numbers failed to return and whether any of these takes significantly longer than the pure link round-trip time configured on the emulator. A link that passes this test stage has at least the nominal capacity and the correct bare-bones RTT.
In the second stage, we continue at this feed rate but add a burst of packets designed to (almost) fill the link's input buffer, something the iperf3 and ping test could not do. In theory, we expect this to result in an RTT that's bare bones plus the input buffer's queue sojourn time, again with only negligible packet loss. If the link passes this stage, we know that the input buffer size is at least what we have configured, as any smaller buffers would overflow and produce packet loss and result in a shorter RTT.
Stage three of the test continues seamlessly at the same feed rate, but at this point, the input buffer is practically full - the link drains it at the same rate as the feed replenishes it. Another burst of the same size as in the second stage now makes the buffer overflow. This should result in packet loss approximately equivalent to the size of the burst, while the RTT should remain unchanged over stage 2. If the link passes this stage, we know that the input buffer size is at most what we want. We can also be confident that there are no hidden bottleneck buffers in the system that we don't know about as these would absorb packets without dropping them, while increasing the RTT.
Stage 4 ramps up the feed rate to 10% above nominal and looks for ~10% packet loss at unchanged RTT. If a link passes this stage, we know that it has at most the nominal capacity.
We then tested this on our tc-based emulations. They always failed stage 2 and 3 of the test wholesale, even when it passed the original test. In other words, the emulation got the rate right, it got the delay right, but it didn't deal with bursts the way we would expect it from a true bottleneck. This looked like a rubber bottleneck!
To an extent, we had been aware of this. The token bucket filters in Linux are designed to assist in restrict bandwidth to users and require a "burst" link rate to be set in addition to the nominal rate. In other words, they cap the average rate to a peak but not the instantaneous rate. However, we had kept the difference to a small amount and so did not consider this to be a likely source of problems. Not so as it would turn out.
With our current link emulation clearly not usable, we needed a Plan B, however, so set upon building a userland link emulator.
The userland link emulator
To build the userland link emulator, we were able to leverage the existing titrator codebase, which already contained a custom token bucket filter very similar to the one needed in the link emulator. It also contained queueing code that could easily be extended to yield a delay queue, meaning the userland link emulator did not take long to develop. Having the new testing tool at hand as well as the existing tests was an added bonus.
After extensive testing, we can now confirm that we are able to emulate GEO links across our entire "poster child" range and MEO links up to 160 Mb/s, with the emulated links passing the tests with flying colours. This currently only leaves us stranded for our 320 Mb/s MEO simulations, for which the emulator is not quite fast enough. We have identified potential for further acceleration, but this will have to wait as it requires significant code refactoring in the packet acquisition routine.
The big surprise then came when we repeated our baselines: Across the board, goodput over the new emulated links was significantly worse than under the tc-based emulator. This was not a bug in the emulator, however, but a result of denying link entry to bursts: When we then tried coded traffic across the same link emulation, we achieved significantly more goodput - multiple times the baseline at low loads, in fact. This behaviour was much closer to what we had seen in the field.
To an extent, this now raises the question as to the validity of results obtained with the previous emulation. These remain valid for any satellite link where allocated customer capacity would have been "traffic shaped" onto a larger bandwidth link shared by multiple customers. They would also in all probability still apply in terms of relative comparison where only uncoded baselines were considered, as these would all have been equally affected in the same direction. We would expect our results to be shifted and/or compressed along the load axis (channels), however.
Lesson learned: It is well known that large buffers on satellite links increase goodput (see Background and Justification section) by absorbing traffic bursts above the nominal rate. Our tc-based emulator clearly did the same and a bit more by allowing such bursts to enter the link without increasing the queue sojourn time.
16 Mb/s GEO sweeps with background traffic
We then set about to run sweeps on our previously mentioned 16 Mb/s GEO case with the 120 kB input queue, using the new userland emulator. The sweeps ran 5-6 configurations for 0, 2, 5, 8, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120, 130, 140,150, 200, 300, and 500 background traffic channels respectively. Each combination was repeated in 10 experiments, each of which took around 20 minutes to complete, resulting in hundreds of hours of experimentation. The configurations used were:
- Uncoded baseline (conventional link)
- Coded with N=30 and M=6
- Coded with N=60 and M=6
- Coded and titrated with N=30 and M=6, with all but 10 kB of the input buffer transferred to the shock absorber queue and the remaining 10 kB in the residual queue
- Dto. with N=60
- Uncoded with a PEPsal proxy (less dense background load range only)
(NB: in the case of titrated configurations, the input buffer size at the actual link is nearly irrelevant as the titrator's strict rate control means that there is never a significant queue build-up in the link input buffer - the shock absorber queue at the titrator takes over this role on coded + titrated links and is dimensioned appropriately).
The following graph shows the total goodput from background traffic plus iperf3 transfer on this link as a function of load for a plain baseline (blue), a link supported by PEPsal at both ends, and various configurations with coding with and without titration:
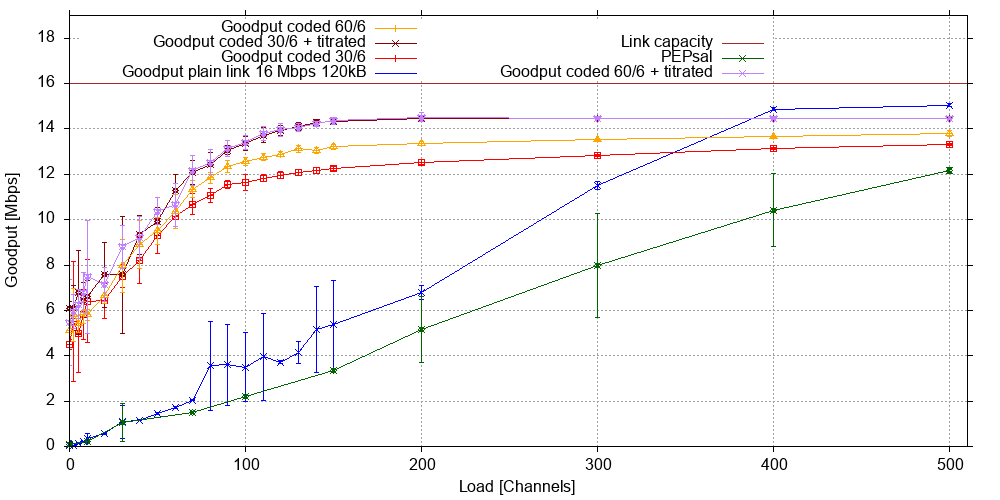
Error bars show the standard deviation among the 10 experiments. Without background traffic, the baseline goodput (blue) starts at very low rates - about 56 kb/s, which is half the iperf3 transfer rate achieved here as it is averaged over the whole 600 seconds of the experiment. With increasing background traffic, the experiments at between 80 and 150 channels produce significant baseline outliers. In this load range, the probability of a connection to a world server picking a large flow size response from the distribution is high enough for this to happen frequently enough to make these flows slow to a crawl, which condemns the associated channel to a long period of low goodput - an effect that has a serious impact due to the relatively low number of channels.This effect disappears at higher loads as the total number of channels provides enough goodput to make up for capacity lost to channels that have slowed to a crawl. At extreme loads, the baseline eclipses all other traffic, however, at this load point, all individual transfers are extremely slow as so many of them have to share the bandwidth: At 500 channels, we can see around 430 simultaneously active flows, which equates to an average of 37.2 kb/s of throughput per flow.
The graph also shows that coded links (red and yellow) yield much better goodput, and don't produce the sort of out outliers that the baseline does - chiefly because the coded traffic does not slow to a crawl and both large and small flows complete at higher rates. The larger generation size (N=60) does noticeably better than the smaller one, presumably because it adds only 10% rather than 20% coding overhead. This difference disappears once we add titration (dark red and purple), which removes excess overhead, and adds roughly another 1 Mb/s of goodput at the demand level where the link reaches saturation at around 200 channels.
Somewhat surprisingly, PEPsal (green) did not result in a goodput gain here. This may be due to the fact that most of the background flows are too short to benefit from proxying, however, they still benefit from coding. Note also that the goodput figures for very high loads cannot reach the link capacity as goodput does not count packet overheads, and link capacity is a throughput limit that does include packet overheads.
The next figure shows the goodput of the 300 second iperf3 TCP transfer under the different scenarios:
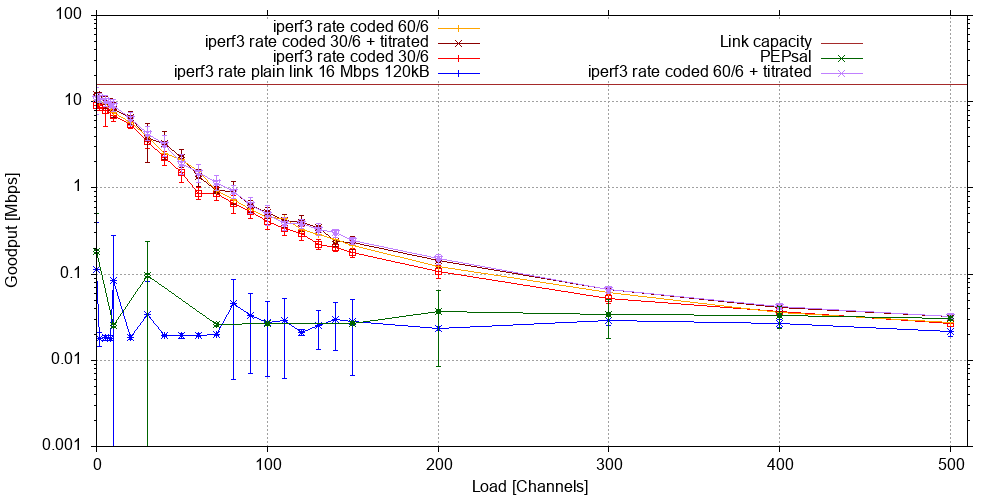
By and large, this graph confirms the previous observation: Coding, with and without titration, lifts all boats. For our large iperf3 transfer, this starts at around two orders of magnitude goodput improvement without background traffic, but even at the previously identified load point of 200 channels when the link is more or less saturated, there is still an improvement by a factor of 4 or more. Again, we see baseline outliers in the previously identified load range, but no outliers among the coded scenarios.
We note here that PEPsal gives significant gains at low background traffic levels and a modest gain at high levels. As expected, coded goodput also declines as the load increases and the available shared channel bandwidth declines.
Maximum link RTT in this scenario is 560 ms, made up from 500 ms bare link RTT and 60 ms maximum queue sojourn time at the world side (assuming that there is no significant queue buildup at the island side link input).
If one increases the input buffer size to 1000 kB, which is a more conventional buffer size, the maximum link RTT nearly doubles to one second. The graph below shows fewer data points as the previous one as we were running out of experimentation time, but nevertheless gives an overall impression:
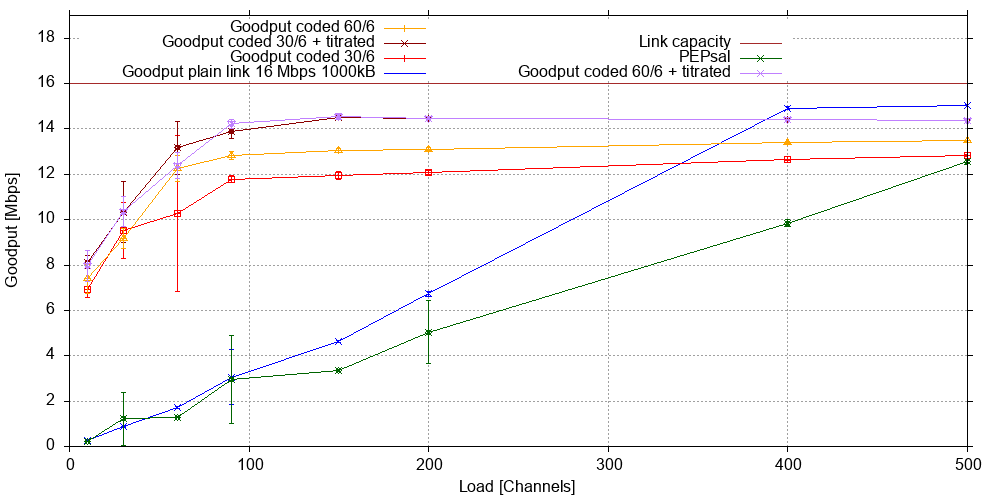
There is no evidence that the large buffer increase yields any beneficial effect on the baseline goodput. PEPsal significantly underperforms at loads above 100 channels, possibly due to stalled connections at these load levels. Coded and titrated traffic benefits from the larger buffer to the tune of about 1.5 to 2 Mb/s at low background traffic levels, and achieves link saturation at around 100 channels. The gain from titration seems a little higher here but would require additional data points to confirm.
Last but not least, let us have a look at how our 300 second iperf3 transfer fared in these experiments. Note that we have investigated fewer load levels here as we were running out of experiment time:
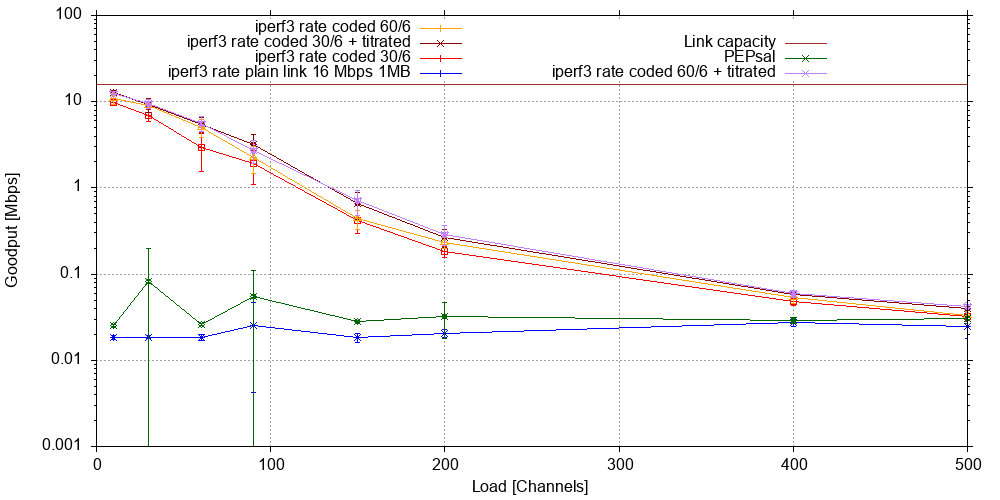
The baseline iperf3 goodput in the 1000 kB scenario has not improved over the 120 kB case - to the contrary. However, PEPsal now exhibits a clear advantage over the baseline across most of the "interesting" load range. Both are dwarfed, however, by the coded configurations, again with the coded and titrated scenarios outperforming all others. At low background traffic levels, the latter accelerate the iperf3 transfer by two orders of magnitude or more until link capacity saturation sets in at around 100 channels. Even at 200 channels, coding and titrating still yields an order of magnitude improvement over baseline.
Note that the larger RTT of the 1000 kB scenario may not warrant the comparatively small goodput gains over the 120 kB scenario, however.
The astute reader may ask why we did not trial PEPsal in combination with coding and titration. In principle, this is possible, and in fact we did try. However, it appears that PEPsal does not reduce its MTU in response to ICMP "Would fragment" messages. As the coding headers of the coded tunnels reduce the MTU across the tunnel, any senders need to adapt accordingly, and in our experiments, full-size PEPsal packets were dropped by the tunnel with no smaller replacements evident in the traces. We are considering whether to change the MTU on the tunnel, although this could be considered "cheating" to an extent.
64 Mb/s MEO sweeps with background traffic
Since the above experiments on a simulated 16 Mb/s GEO link, we have also completed a series of experiments on simulated MEO links with a nominal bit rate of 64 Mb/s in each direction and 400 and 1000 kB of input queue, respectively. We present the results for 400 kB below. The first figure shows the goodput:
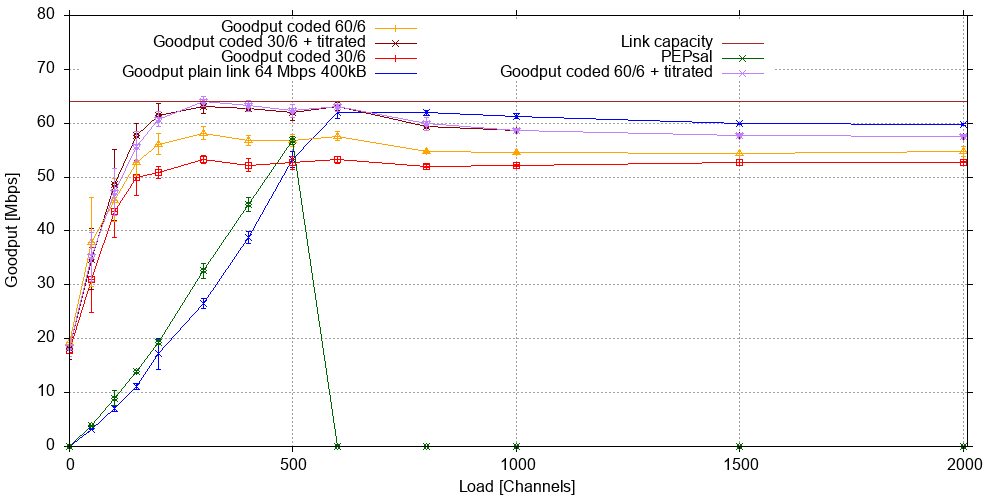
Naively, one might assume that 4x the bandwidth should allow four times the load, and thus we chose to load the link with up to 2000 channels. However, due to the lower RTT in MEO systems, the congestion window in each channel opens faster, increasing the goodput per channel until the demand saturates the link capacity at around 600 channels.
Once again, we note that the overall goodput for coded traffic significantly exceeds that of uncoded traffic in this range of up to 600 channels. Also, once again titration ekes out a bit of extra goodput in this load range. PEPsal (green curve) also improves significantly over over baseline in this range, however, in our experiments, loads over 500 channels caused the island-side PEP to reject almost all connection attempts from clients, meaning near zero goodput. As experiments were interleaved, we can exclude other simulator failures. We have yet to investigate whether there is a parameter in PEPsal that may be changed to avoid this.
But not only the total goodput increases under coding and PEPsal, our individual long iperf3 transfer also fared much better, starting at 3 orders of magnitude without background traffic, and still managing 164% improvement over baseline at 500 channels - a point at which our baseline already featured 83.1% link utilisation:
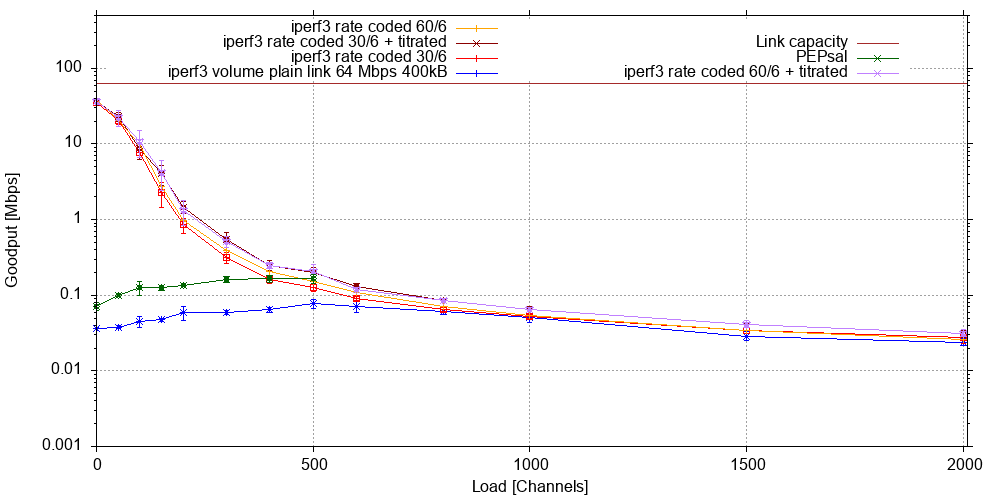
Even at large loads well within link saturation, coding with titration still brings benefits for such long flows, with an almost 32% higher rate at 2000 channels.
Next steps
Originally, we had hoped to cover all of our poster child cases: 8 Mb/s, 16 Mb/s, 32 Mb/s, and 64 Mb/s GEO, and 32, 64, 160 and 320 Mb/s MEO, but to date, we have really only covered one GEO and one MEO case. Investigating at least some of the remaining cases will keep us busy for the next few months. We are also looking at making improvements to the userland link emulator to enable us to cover the 160 and 320 Mb/s MEO scenarios to a full extent, and have a kernel link emulator under development.
The next step then will be high load burn tests: Can the coding and titrating software run for extended periods of time?
Another question will be as to whether we can combine coding and titrating on a single machine. This should be possible even with the current versions using intermediate function block devices, at least in theory, and would be very desirable for deployment. But will this work in practice?
The next step thereafter would be a trial deployment on an actual link.
Project Evaluation
The core objective of the project, the titrator software, was achieved relatively soon after the start of the project, and intergration into our simulator soon thereafter. Covid-19 did to a certain extent throw its spanners into the works, from making team meetings difficult (we used Zoom but it's just not a replacement for face-to-face time in front of a big screen where one can open multiple windows at once, or a whiteboard) to temporarily denying us lab access and necessitating the development of "workaround" software so we could keep experiments running by avoiding machines that had stalled. But: We were grateful for the extension, which allowed us to get back on track and complete at least some of our planned experiments successfully.
The project supported a student of Pacific Island descent through the first year of his PhD, and has allowed us to attract another. It has also helped attract a very capable Honours student with Pacific connections who intends to progress to PhD study.
The outcomes of the project to date are so promising that we are now looking at taking the research out of the lab and back into the field again, with a view to wider deployment.
The project has finally been able to show that network coding can make a significant goodput difference to satellite links, and that titration improves further on this result. We now have a working coder / decoder, a working titrator, and - as an unexpected side product - a working link configuration tester and userland link emulator (a kernel version is under development by the aforementioned Honours student). The immediate next step will be to confirm our results for the remainder of our representative "poster child" cases as well as tests to confirm the robustness of the coding and titration software: Will it run continuously for weeks or more at a time rather than for the few minutes our current experiments operate it for? The next logical step is then a move to trial deployments on actual satellite links.
We learned a number of important lessons from the project:
- Realising that our existing satellite emulation needed closer scrutiny than could be obtained with the standard tools gave us our "Eureka" moment: An emulation that had previously passed all available tests broke, and subsequent investigation led us down the path to develop a better testing tool and, subsequently, a better emulator.
- We have learned that allowing a link emulation to pass traffic bursts, while unrealistic, lets TCP accelerate much beyond its normal level, thereby artificially inflating baselines by a very significant amount.
- Allowing traffic bursts to pass onto the link also had the effect of delaying queue fill, while allowing stronger TCP surges toward the link, and subsequently longer periods of subsiding traffic leading to drainage. This produced queue oscillation with significant overflows at lower load levels than we now see it at, so we had to extent our load scan ranges upwards.
- Coding yields a significant goodput gain over baseline in load ranges below link saturation.
- Titration improves noticeably over pure coding, and makes the choice of code less critical.
- Platform stability is key if one wants to orchestrate 140 computers in a high load experiment. The last year has allowed us to identify a number of factors that led to downtimes. Our Raspberry Pi clients on the "island" side of the simulator do not respond kindly to power cycling, which resulted in over a dozen damaged SD cards that the Pis use as their main memory. We are now progressively transitioning to eMMC-based RaspiKeys as a hopefully less sensitive form of memory, and have managed to find an unused uninterruptible power supply (UPS) that we will use to buffer mains supply to the Pis. For our large servers, we have learned the value of having BMCs (board management controllers) with an IP management interface (IPMI) that allow remote rebooting. This feature was an absolute godsend during Auckland's lockdowns.
- We have historically used the university's campus network to distribute commands and configuration to our larger servers, as well as retrieve packet capture data through this channel. Over the last year, we saw a growing number of incidents where this communication failed during batch experiments. The most likely explanation for this is that the network around the simulator facility became busier during this time (a significant amount of New Zealand's Covid-19 analysis and modelling research was conducted in our building) and our large number of connections simply timed out. As a result, we are now considering the construction of a dedicated command and control network for the simulator.
| Indicators | Baseline | Project activities related to indicator | Outputs and outcomes | Status |
|---|---|---|---|---|
| How do you measure project progress, linked to the your objectives and the information reported on the Implementation and Dissemination sections of this report. | Refers to the initial situation when the projects haven’t started yet, and the results and effects are not visible over the beneficiary population. | Refer to how the project has been advancing in achieving the indicator at the moment the report is presented. Please include dates. | We understand change is part of implementing a project. It is very important to document the decision making process behind changes that affect project implementation in relation with the proposal that was originally approved. | Indicate the dates when the activity was started. Is the activity ongoing or has been completed? If it has been completed add the completion dates. |
| Queueing system developed | Queueing system did not exist | Queueing system design and development in C | Queueing system available for integration and deployment | Completed early February 2020 |
| Age check for coded packets added | Feature did not exist | Implemented as part of the queueing system | Available for integration and deployment | Completed early February 2020 |
| Generation completeness check added | Feature did not exist | Implemented as part of the queueing system | Available for integration and deployment | Completed early February 2020 |
| Integration and testing of queueing system | Queueing system did not exist | Setup of titrator machines, integration into the simulator network, reconfiguration of the network, adaptation of the experiment harness software, testing, bug fixing | Queueing system available for regular experimentation | Completed end of March 2020 |
| GEO simulations with queueing system complete | No simulations undertaken | Simulation for 16, 32, and 64 Mbps GEO links at different load levels | Set of simulations complete | Complete for 16 Mb/s, ongoing for other link scenarios, delayed by change in emulation |
| MEO simulations with queueing system complete | GEO simulations with queueing system complete | Simulation for 32, 64, 160 and 320 Mbps MEO links at different load levels | Set of simulations complete | To be done, delayed by change in emulation |
| Conference papers/presentations delivered | Unwritten / not presented | Wrote and submitted one paper | Late start of project and change in emulation meant that we missed the APRICOT deadlines. GLOBECOM paper was less complete than we had hoped for and was rejected; however we now have good material for several papers in 2021. | Ongoing |
Gender Equality and Inclusion
Being about Internet connectivity with a focus on Pacific Islands, our project is as such inclusive of any Internet user regardless of gender and other attributes. We also try and reflect this in our project team.
Students of a Pacific Island background are a recognised equity group at the University of Auckland and, at graduate level, still "rare are hen's teeth". We have historically been lucky to be able to recruit a small number of such students, including 'Etuate Cocker, who complete his PhD with us in 2016 and now works for Exclusive Networks in a senior role building infrastructure management capacity in the Pacific. As part of this project, we were also able to lure our former MSc student Fuli Fuli back into the fold as a PhD student last year. We are also looking forward to welcoming Wayne Reiher from Kiribati as a PhD student on a NZ Scholarship from MFAT (Ministry of Foreign Affairs and Trade). He was hoping to start in 2021, but with NZ's borders still closed, this has had to be postponed to early 2022.
Sadly, Wanqing Tu, our only female team member so far, left the university for a new position at Durham University in the UK in early 2021. We wish her luck in new role as an Associate Professor there.
Project Communication Strategy
As a research project, we predominantly focus on two areas: Scholarly publications and communication with those sectors of industry likely to use the outcome of our research. Due to the delays from Covid-19 and the change in satellite emulation, we are only now getting to the point where we have enough results to communicate, however these results are now arriving at a fast rate, and the second quarter of 2021 will see us concentrate on dissemination.
We still plan on targeting IEEE INFOCOM, Globecom and ICC as the premier venues for scholarly publication. However, now that our results demonstrate that coding and titration significantly lift both the overall performance of (at least geostationary) satellite links, we will also be directing our communication to stakeholders who may be interested in assisting with an all-of-island pilot deployment. These will be island ISPs that use satellite link or providers that install and commission such links, so we will be targeting venues such as APRICOT and PACNOG for this purpose.
Recommendations and Use of Findings
Our work to date has shown us that running simulations in an actual network allows us to replicate effects seen in actual systems with actual background traffic. We have the traces - there is no argument about whether real network stack would behave in this way: Our data was produced in real time by real network devices.
On the flip side, we have learned that a hardware-based simulator is a complex beast that comes with downtimes - from equipment failures to annual electrical testing to software issues that necessitate redesign. We already knew that it is important to always question critically what one is doing. This project's late but fruitful insight as to the appropriateness of its link simulation was a case in point: It wasn't enough just to test for correct latency and bandwidth, we also needed to test for correct dynamic behaviour to find out that we had an emulation that gave our baseline scenario an unrealistic and unfair advantage.
We have also learned that we will probably need to isolate our command and control network from the general campus network in order to avoid interference to our control traffic during busy periods on the campus network.
Having the results in hand that emerged over the last few months, we feel very confident going forward: We finally know that coding and titration work, and work well. While we still need to demonstrate this in the higher rate GEO and the MEO domain, we do not expect too many nasty surprises there.
At this point, we believe that we have good news for operators of satellite based Internet connectivity, however we will need their cooperation in the field and in space to deploy what we have developed.
We were very grateful for the flexibility shown by ISIF Asia both in terms of reporting deadlines and use of budget. This allowed us to work around some of the Covid-19 impact on our operations.
Bibliography
[1] J. K. Sundararajan, D. Shah, M. Medard, S. Jakubczak, M. Mitzenmacher, J. Barros. "Network Coding Meets TCP: Theory and Implementation", Proceedings of the IEEE, 99 (3), 2011, pp. 490-512
[2] U. Speidel and L. Qian, "Simulating Satellite Internet Performance on a Small Island". APAN – Research Workshop, Auckland, 2018, pp. 14-21. (best paper award)
[3] G. Appenzeller, I. Keslassy, N. McKeown, “Sizing Router Buffers,” ACM SIGCOMM Comput. Commun. Rev., 34 (4), Aug. 2004, pp. 281–292
[4] J. Gettys and K. Nichols, “Bufferbloat: Dark Buffers in the Internet,”Communications of the ACM, 55 (1), January 2012, pp. 57–65
[5] U. Speidel and L. Qian, “Striking a Balance between Bufferbloat and TCP Queue Oscillation in Satellite Input Buffers,” IEEE Global Communications Conference, GLOBECOM 2018, Abu Dhabi, United Arab Emirates, December 9-13, 2018, pp. 1–6.
This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License 

